Uno de los casos más comunes con los que se puede ejemplificar una aplicación de Machine Learning es la segmentación de clientes. Algo que todas las empresas desean hacer es identificar grupos de clientes que tengan un perfil similar para poder aplicar acciones sobre ellos, por ejemplo aplicar diferentes campañas de marketing según el perfil de cada grupo. Aquí veremos un ejemplo de cómo realizar una segmentación de clientes usando ML.NET.
El siguiente ejemplo es tomado del proyecto machinelearning-samples y personalizado para incluir la predicción del perfil de un cliente. El código fuente del proyecto personalizado se puede descargar aquí. NOTA: Leer el archivo readme del proyecto luego de leer este post te ayudará a entender mejor el código fuente.
El proyecto plantea el siguiente problema: Cómo identificar diferentes grupos de clientes con un perfil similar pero sin tenerlos clasificados o marcados previamente. Este es un problema muy común en las empresas que desean iniciar una segmentación de clientes pero todavía no saben qué variables utilizar o con qué lista de categorías agruparlos.
Dataset (datos de entrada)
El dataset para generar el modelo de machine learning es un ejemplo de una serie de campañas de marketing y el historial de los clientes que compraron alguna de esas campañas. En el archivo readme del proyecto se explica más sobre este conjunto de datos, aquí no lo detallo mucho ya que la mayoría de estas variables serán descartadas y más adelante se creará una abstracción de estos datos para representarlos en una tabla simple de clientes y ordenes de compra.
Técnica de Clustering
La técnica más recomendada para resolver este tipo de clasificaciones es la técnica de clustering. Una de las ventajas de usar ML.NET para el desarrollo de estos proyectos es que no se requiere ser experto en técnicas y algoritmos de Machine Learning. Por lo tanto, solo es necesario saber que la técnica de clustering es la técnica recomendada para identificar grupos o ‘clusters’ con características relacionadas o similares donde no tenemos una lista de categorías previamente elaborada.
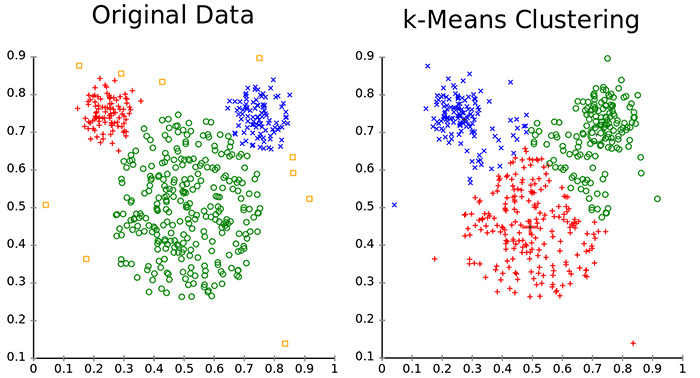
Para determinar el número de clusters en el cual agruparemos nuestros datos utilizaremos un algoritmo llamado k-means. Este algoritmo asigna ejemplos tomados del dataset a un número ‘k’ de clusters. Entender este algoritmo no es complejo pero toma un poco de tiempo, para propósitos de este ejemplo es necesario entender solo tres aspectos.
- El número ‘k’ de clusters a agrupar es un parámetro que será dado al algoritmo.
- El algoritmo minimiza la distancia entre un punto de los datos y un punto céntrico llamado centroid o midpoint del cluster.
- Los clusters se formaran con los puntos que tengan características similares.
Esto se entenderá mejor de forma gráfica más adelante. Para eso usaremos otra técnica de Machine Learning llamada PCA. Esta técnica nos ayuda a tomar un dataset con una serie de variables y encontrar las variables más representativas para trabajar solo con ellas. Está técnica también es conocida como reducción de dimensiones ya que permite tomar un dataset con ‘n’ variables y reducirlas a 2 o 3 variables (x,y,z) para poder representar los datos de forma gráfica.
En resumen: para construir nuestro modelo de segmentación de clientes seguiremos los siguientes pasos.
- Preparación de la data para armar una tabla simple de clientes y sus ordenes de compra realizadas.
- Creación de un modelo usando la técnica de Clustering para agrupar los datos según sus características en un número ‘k’ de clusters.
- Entrenamiento del modelo con nuestros datos.
- Evaluación de la exactitud del modelo.
- Consumir el modelo para agrupar clientes en clusters
- Agregar método de predicción para determinar el cluster al que pertenece un solo cliente.
Preparación de la data.
Una vez descargado el código fuente, encontrarán dos proyectos de consola.
- CustomerSegmentation.Train En este proyecto se entrena y se crea el modelo de ML.NET
- CustomerSegmentation.Predict En este proyecto se realizará la clasificación en clusters y la predicción del cluster de un cliente
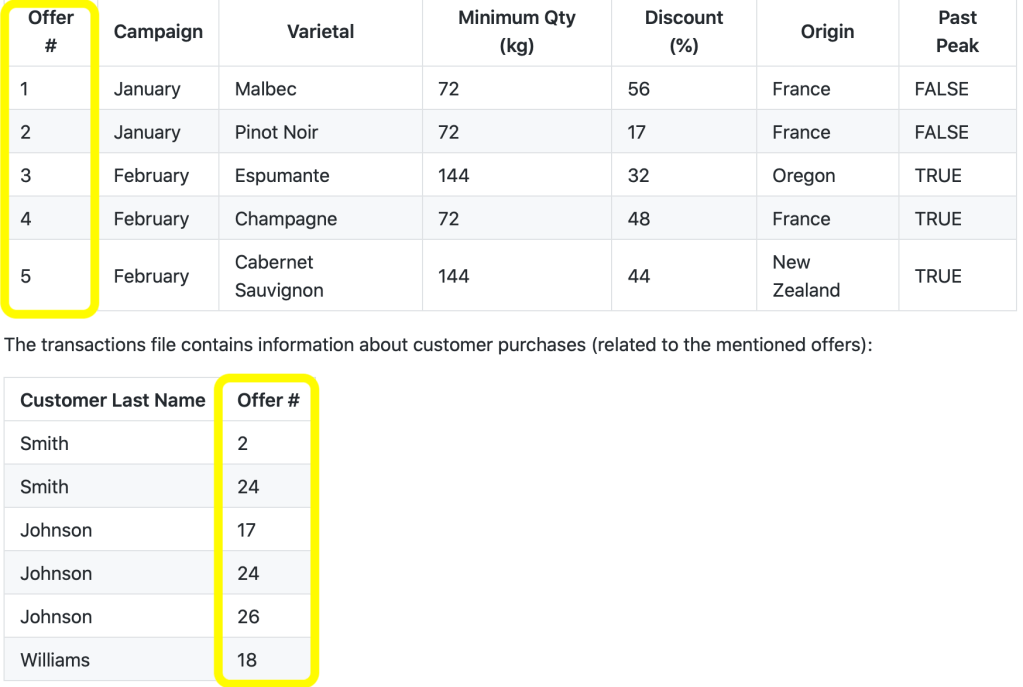
Para procesar los datos se requiere crear una tabla que una los clientes y las ordenes que compró en un solo registro para que puedan ser analizadas como las características de un cliente. Esto se realiza al inicio del programa con la siguiente linea.
//STEP 0: Special data pre-process in this sample creating the PivotTable csv file
DataHelpers.PreProcessAndSave(offersCsv, transactionsCsv, pivotCsv);
El resultado de esta función es una tabla con la siguiente forma:

En esta tabla las filas representan a cada cliente y las columnas son las campañas realizadas, el valor de las celdas representa si el cliente realizó la compra de esa campaña.
Construcción del modelo
Para construir el modelo en ML.NET se debe definir un Pipeline. En este objeto no se ejecuta ningún proceso, solo se define cómo se va a construir el modelo. La creación del Pipeline se realiza usando el objeto ‘MLContext’ que es el análogo al DBContext en EntityFramework. En este objeto se pueden ir agregando objetos de tipo ‘Transform’ y ‘Trainer’ que son como pasos a seguir para obtener el modelo de ML.NET deseado.
//Create the MLContext to share across components for deterministic results
MLContext mlContext = new MLContext(seed: 1); //Seed set to any number so you have a deterministic environment
// STEP 1: Common data loading configuration
var pivotDataView = mlContext.Data.LoadFromTextFile(path: pivotCsv,
columns: new[]
{
new TextLoader.Column("Features", DataKind.Single, new[] {new TextLoader.Range(0, 31) }),
new TextLoader.Column(nameof(PivotData.LastName), DataKind.String, 32)
},
hasHeader: true,
separatorChar: ',');
// STEP 2: Configure data transformations in pipeline
var dataProcessPipeline = mlContext.Transforms.ProjectToPrincipalComponents(outputColumnName: "PCAFeatures", inputColumnName: "Features", rank: 2)
.Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "LastNameKey", inputColumnName: nameof(PivotData.LastName), OneHotEncodingEstimator.OutputKind.Indicator));
// STEP 3: Create the training pipeline
var trainer = mlContext.Clustering.Trainers.KMeans(featureColumnName: "Features", numberOfClusters: 3);
var trainingPipeline = dataProcessPipeline.Append(trainer);
Los pasos definidos en este Pipeline son:
- Cargar los datos desde el archivo .csv generado anteriormente, se define una columna de tipo vector con el nombre ‘Features’ para cargar los valores de las campañas compradas por el cliente (las columnas 0-31 del archivo .csv), se define además una columna «LastName» para cargar el nombre del cliente (la columna 32 del archivo .csv).
- Luego de cargados los datos se los debe procesar. Agregando la transformación (‘Transform’) ‘ProjectToPrincipalComponents’ se está aplicando la técnica PCA para tomar solo las 2 columnas más relevantes (parámetro ‘rank’) para la construcción del modelo y los clusters.
- El tercer paso es definir el algoritmo de entrenamiento a utilizar. En este caso se utiliza el algoritmo ‘Kmeans’ al cual se le pasan dos parámetros: ‘featureColumnName’ es el nombre de la columna con las características a evaluar, en este caso «Features», y ‘numberOfClusters’ es el número de clusters en el que se desea agrupar los clientes durante el entrenamiento.
Entrenamiento del modelo
Luego de definir el Pipeline para la creación del modelo podemos pasar al entrenamiento del modelo. Esto se realiza utilizando los datos cargados anteriormente en el objeto ‘pivotDataView’ y ejecutando la siguiente instrucción.
//STEP 4: Train the model fitting to the pivotDataView
Console.WriteLine("=============== Training the model ===============");
ITransformer trainedModel = trainingPipeline.Fit(pivotDataView);
Evaluar el modelo
La evaluación de la precisión de un modelo suele ser un capítulo entero en un curso de Machine Learning. Para nuestra fortuna ML.NET tiene ya implementadas las funciones de evaluación como la matriz de confusión y UAC para solo utilizarlas y saber si nuestro modelo es confiable o no. Esto lo realizamos con las siguientes instrucciones.
//STEP 5: Evaluate the model and show accuracy stats
Console.WriteLine("===== Evaluating Model's accuracy with Test data =====");
var predictions = trainedModel.Transform(pivotDataView);
var metrics = mlContext.Clustering.Evaluate(predictions, scoreColumnName: "Score", featureColumnName: "Features");
ConsoleHelper.PrintClusteringMetrics(trainer.ToString(), metrics);
En el objeto ‘metrics’ se cargarán los valores de la calificación del modelo, mientras más cercanos sean a 1 los valores de la calificación más confiable será el modelo construido.
En este punto ya tenemos un modelo entrenado y evaluado, lo único que resta es grabar en modelo en un archivo .zip con las siguientes instrucciones.
//STEP 6: Save/persist the trained model to a .ZIP file
using (var fs = new FileStream(modelZip, FileMode.Create, FileAccess.Write, FileShare.Write))
mlContext.Model.Save(trainedModel, pivotDataView.Schema, fs);
Si ejecutamos todos los pasos vistos hasta ahora y contenidos en el proyecto ‘CustomerSegmentation.Train‘ se verá una aplicación de consola que imprimirá los resultados de la siguiente forma.
Consumir el modelo.
Para consumir el modelo que acabamos de crear vamos a usar el proyecto ‘CustomerSegmentation.Predict‘. Para consumir el modelo vamos a seguir tres pasos.
- Cargar el modelo de ML.NET
- Cargar los datos nuevos a predecir.
- Ejecutar la predicción del modelo con el método ‘Transform’
Para este propósito se ha creado la clase ‘ClusteringModelScorer’ con los métodos necesarios para ejecutar les tres pasos indicados.
La carga del modelo se lo realiza con el siguiente método.
public ITransformer LoadModel(string modelPath)
{
_trainedModel = _mlContext.Model.Load(modelPath, out var modelInputSchema);
return _trainedModel;
}
La carga de los datos a predecir es muy similar a la carga de datos que se realizó para el entrenamiento del modelo, se utiliza la misma estructura del archivo pivot.csv y la misma se define en el método ‘LoadFromTextFile’.
var data = _mlContext.Data.LoadFromTextFile(path:_pivotDataLocation,
columns: new[]
{
new TextLoader.Column("Features", DataKind.Single, new[] {new TextLoader.Range(0, 31) }),
new TextLoader.Column(nameof(PivotData.LastName), DataKind.String, 32)
},
hasHeader: true,
separatorChar: ',');
//Apply data transformation to create predictions/clustering
var tranfomedDataView = _trainedModel.Transform(data);
var predictions = _mlContext.Data.CreateEnumerable <ClusteringPrediction>(tranfomedDataView, false)
.ToArray();
//Generate data files with customer data grouped by clusters
SaveCustomerSegmentationCSV(predictions, _csvlocation);
El resultado de la ejecución de este código será la clasificación de los datos ingresados en los respectivos clusters a los que cada cliente corresponda según sus características.
Si ejecutamos el proyecto el resultado en consola se verá de esta forma.
Adicionalmente el método ‘SaveCustomerSegmentationPlotChart()’ grabará un gráfico XY con la representación gráfica de los clientes y sus clusters diferenciados por colores, de la siguiente forma.
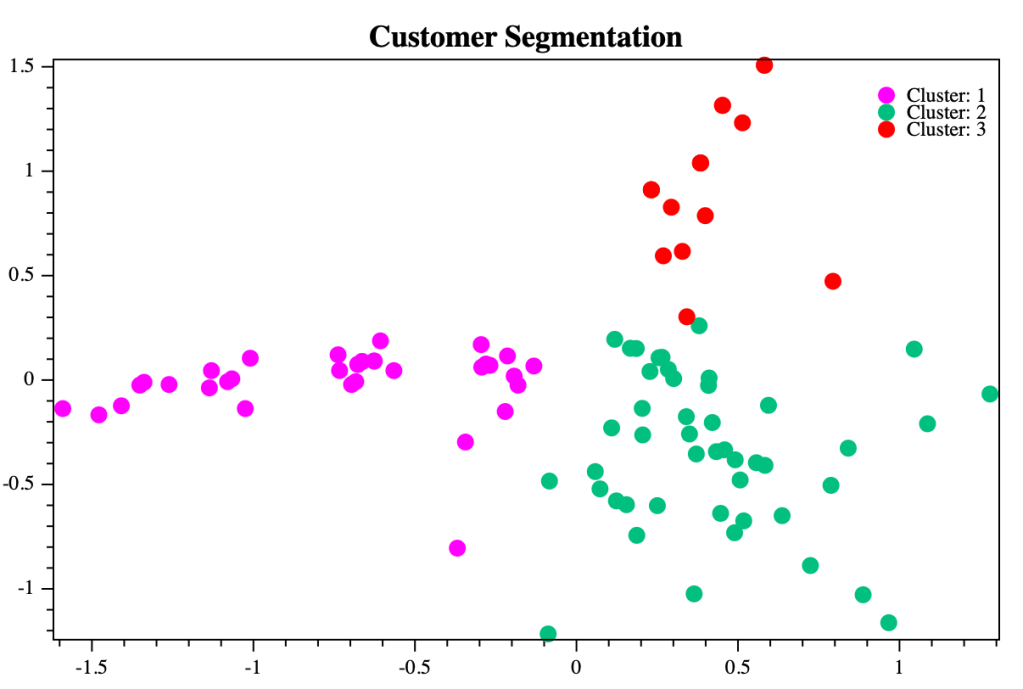
En el gráfico anterior se puede ver tres diferentes clusters, o grupos de clientes. En este caso dos de ellos están bien diferenciados (cluster 1 en azul y cluster 2 en verde). Sin embargo, algunos clientes del cluster 3 estás sobrepuestos con algunos clientes del cluster 2, lo cual también puede pasar con grupos de clientes.
Predicción
Hasta aquí el proyecto solo realiza la clasificación de un grupo de clientes y su resultado se graba en un archivo de texto. Pero en casos más reales seguramente vamos a necesitar realizar la predicción de un cliente nuevo para saber en qué grupo o cluster encaja. Para esto, en proyecto personalizado, he agregado el método ‘PredictCustomerClusters’ que realiza la predicción de un cliente.
El primer paso es definir un objeto ‘ModelInput’ con la misma estructura que el archivo de texto pivot.csv. Solo por efectos de este ejemplo, la clase está definida en el mismo archivo ‘ClusteringModelScorer’.
private class ModelInput
{
[LoadColumn(0), VectorType(32), ColumnName("Features")]
public float[] Features = new float[31];
[LoadColumn(1), ColumnName("LastName")]
public string LastName;
}
El siguiente paso es crear un objeto ‘CreatePredictionEngine’, el cual contiene un objeto de entrada (ModelInput) y uno de salida (ClusteringPrediction). Luego instanciamos un objeto ‘ModelInput’ simulando ser el cliente nuevo que queremos predecir su clasificación.
Finalmente, invocamos el método ‘Predict’ de nuestro objeto ‘CreatePredictionEngine’ y le pasamos como parámetro la data de nuestro objeto ‘ModelInput’. El método completo quedará de esta forma:
public void PredictCustomerClusters()
{
var predEngine = _mlContext.Model.CreatePredictionEngine<ModelInput, ClusteringPrediction>(_trainedModel);
//Load sample data for prediction
var data = new ModelInput
{
Features = new float[] { 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 },
LastName = "Mera"
};
// Try model on sample data
ClusteringPrediction result = predEngine.Predict(data);
List<ClusteringPrediction> enumResult = new List<ClusteringPrediction>
{
result
};
Console.WriteLine($"\nCustomer: {data.LastName} | Prediction: {result.SelectedClusterId} cluster");
Console.WriteLine($"Location X: {result.Location[0].ToString()} | Location Y: {result.Location[1].ToString()} ");
SaveCustomerSegmentationPlotChartSingle(enumResult.ToArray(), "customerSegmentation2.svg");
OpenChartInDefaultWindow("customerSegmentation2.svg");
}
Para ejecutar la predicción debemos reemplazar en el archivo ‘Program.cs’ el método original ‘CreateCustomerClusters’ por nuestro nuevo método ‘PredictCustomerClusters’. El resultado de la ejecución se verá en la consola de la siguiente forma.
Diviértanse descargando el proyecto y aplicando todas las mejoras que se les ocurra!
Artículo Relacionado: Videos de ML.NET – Machine Learning explicados en español.
