
Una de las ventajas de usar el framework ML.NET para la ciencia e ingeniería de datos es la posibilidad de crear experimentos para la creación de modelos de Machine Learning de manera automatizada. En este post vamos a usar la clase MulticlassClassificationExperiment incluida en el paquete Microsoft.ML.AutoML para crear un modelo para predecir la probabilidad de cancelación o cambio en la reserva de un hotel.
El código fuente del proyecto se puede descargar de este repositorio en GitHub
Problema
Tenemos un dataset con el histórico de las reservas de varios hoteles y el registro de los cambios que tuvo la reserva. Con estos datos vamos a crear un modelo de Machine Learning para predecir si una reserva puede ser cancelada, modificada o no tener cambios. Este escenario puede ser útil para ofrecer un seguro de cancelación de reserva a un menor o mayor costo según el resultado de la predicción.
Dataset
Contamos con un Dataset tomado de kaggle y modificado para marcar tres categorías en la columna de reservation_status, esta puede tener los valores: Booking-Changed; Canceled; Check-Out
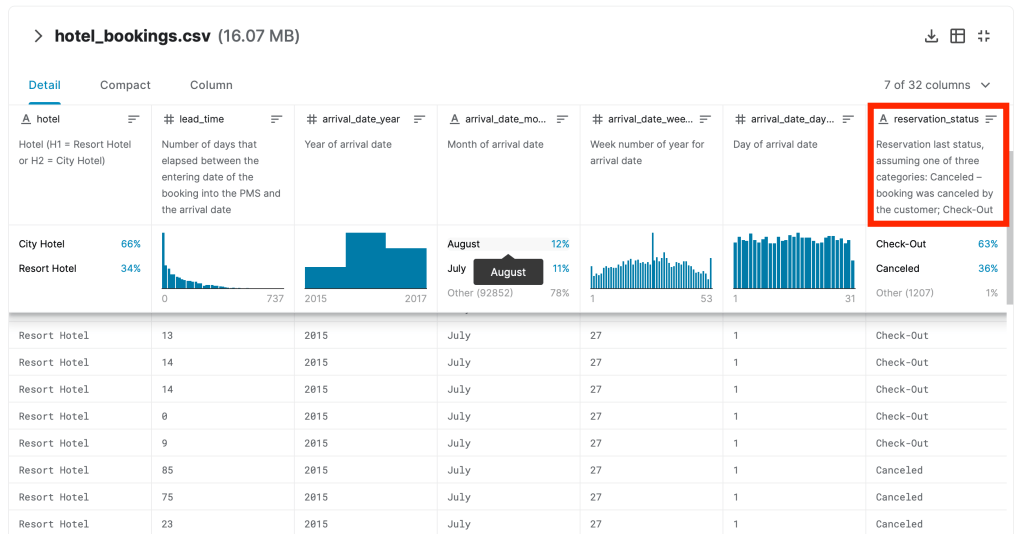
Solución
Crearemos un modelo de Machine Learning usando el framework ML.NET. Ya que son tres categorías las que queremos predecir (Booking-Changed; Canceled; Check-Out) debemos crear un modelo de clasificación multiclase (multiclass classification). Lo haremos de forma automática para que el framework seleccione el mejor algoritmo y los mejores parámetros para nuestro dataset, no tendremos que preocuparnos por la parte matemática, estadística o el tipo de algoritmo a utilizar.
Ya que nuestro modelo debe ser de clasificación multiclase (multiclass classification) usaremos el método CreateMulticlassClassificationExperiment para crear el modelo de forma automática.
Como en toda solución de Machine Learning seguiremos los siguientes pasos para crear el modelo.
- Preparar y cargar los datos de entrenamiento y prueba
- Entrenar el modelo para le predicción de los valores deseados
- Evaluar la precisión del modelo
- Consumir el modelo desde una aplicación
Los datos los cargaremos en un objeto IDataView desde un archivo de texto con el siguiente código
// Load Data
var tmpPath = GetAbsolutePath(TRAIN_DATA_FILEPATH);
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<ModelInput>(
path: tmpPath,
hasHeader: true,
separatorChar: '\t',
allowQuoting: true,
allowSparse: false);
var splitData = mlContext.Data
.TrainTestSplit(trainingDataView, testFraction: 0.15);
El método mlContext.Data.TrainTestSplit() nos sirve para tomar una muestra de nuestro dataset que será usado para probar el modelo creado
Para entrenar el modelo usaremos el método CreateMulticlassClassificationExperiment, al invocarlo necesitamos especificar el tiempo en segundos que queremos que dure el experimento, dependiendo del tamaño de nuestro dataset mientras más tiempo dure el entrenamiento más algoritmos serán probados hasta encontrar el de mejor precisión. El código para crear el experimento es el siguiente.
// STEP 2: Run AutoML experiment
Console.WriteLine($"Running AutoML Multiclass classification experiment for {ExperimentTime} seconds...");
ExperimentResult<MulticlassClassificationMetrics> experimentResult = mlContext.Auto()
.CreateMulticlassClassificationExperiment(ExperimentTime) .Execute(trainingDataView, labelColumnName: "reservation_status");
Para usar este método dentro del objeto de contexto mlContext debemos instalar el paquete nuget Microsoft.ML.Auto
using Microsoft.ML.AutoML;
Hasta ahí ese es todo el código que necesitamos para crear nuestro modelo de clasificación multiclase. Pero antes de poder usarlo debemos conocer sus métricas y su precisión para hacer predicciones. Lo primero que podemos observar es el algoritmo seleccionado para el modelo y las métricas que lo calificaron como el mejor algoritmo para nuestros datos. Esto lo podemos hacer con este código
// STEP 3: Print metric from the best model
RunDetail<MulticlassClassificationMetrics> bestRun = experimentResult.BestRun;
Console.WriteLine($"Total models produced: {experimentResult.RunDetails.Count()}");
Console.WriteLine($"Best model's trainer: {bestRun.TrainerName}");
Console.WriteLine($"Metrics of best model from validation data --");
PrintMulticlassClassificationMetrics(bestRun.ValidationMetrics);
El siguiente paso es probar el modelo con datos de prueba no incluidos en el entrenamiento y ver si las métricas son similares a las métricas del entrenamiento del modelo.
// STEP 4: Evaluate test data
IDataView testDataViewWithBestScore = bestRun.Model.Transform(splitData.TestSet);
var testMetrics = mlContext.MulticlassClassification.CrossValidate(testDataViewWithBestScore, bestRun.Estimator, numberOfFolds: 5, labelColumnName: "reservation_status");
Console.WriteLine($"Metrics of best model on test data --");
PrintMulticlassClassificationFoldsAverageMetrics(testMetrics);
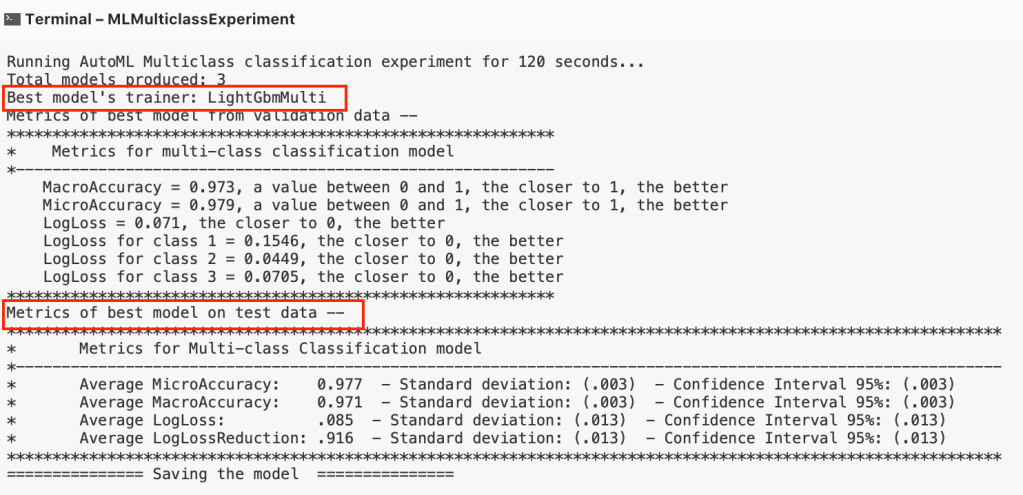
Los resultados de este experimento en resumen son los siguientes
- Mejor algoritmo seleccionado: LightGbmMulti. Una de las ventajas de generar un modelo de forma automática es que la selección del algoritmo no está sesgada por la preferencia del data scientist, durante el experimento se han probado varios algoritmos y configuraciones
- Precisión del modelo: 97%
- Con los datos de prueba se obtuvo en promedio un 97% de precision en las predicciones lo que nos una confianza bastante buena para poder usar nuestro modelo generado
El siguiente paso es guardar el modelo en un archivo .zip para luego usarlo desde una aplicación
// Save model
SaveModel(mlContext, bestRun.Model, MODEL_FILEPATH, trainingDataView.Schema);
Como último paso crearemos una clase ConsumeModel y un método Predict() para consumir el modelo y probar una predicción con los datos de una nueva reserva de hotel.
// Create new MLContext
MLContext mlContext = new MLContext();
// Load model & create prediction engine
string modelPath = @"MLModel.zip";
ITransformer mlModel = mlContext.Model.Load(modelPath, out var modelInputSchema);
var predEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(mlModel, modelInputSchema);
// Use model to make prediction on input data
ModelOutput result = predEngine.Predict(input);
return result;
Una recomendación de diseño es crear las clases ConsumeModel, ModelInput y ModelOutput en un solo proyecto, puede ser el mismo en el que creamos y entrenamos el modelo, de esa forma, En la aplicación para consumir el modelo y hacer una predicción con nuevos datos solo deberemos referencias el proyecto con la clase ConsumeModel y no será necesario instalar los paquetes de Microsoft.ML.
El código en la aplicación para predecir el cambio de estado en una reserva de hotel se verá así.
Console.WriteLine("Tiempo de anticipacion: ");
string leadTime = Console.ReadLine();
Console.WriteLine("Cuarto reservado: ");
string cuartoReservado = Console.ReadLine();
Console.WriteLine("Precio promedio: ");
string adr = Console.ReadLine();
Console.WriteLine("Pais: ");
string country = Console.ReadLine();
Console.WriteLine("Cambios previos: ");
string cambiosPrevios = Console.ReadLine();
ModelInput bookingData = CreateBookingData(leadTime, cuartoReservado, cambiosPrevios, adr, country);
ModelOutput bookingPredict = PredecirCambioReserva(bookingData);
Console.WriteLine($"\n\nActual Reservation_status: {bookingData.Reservation_status} \nPredicted Reservation_status value {bookingPredict.Prediction} \nPredicted Reservation_status scores: [{String.Join(",", bookingPredict.Score)}]\n\n");
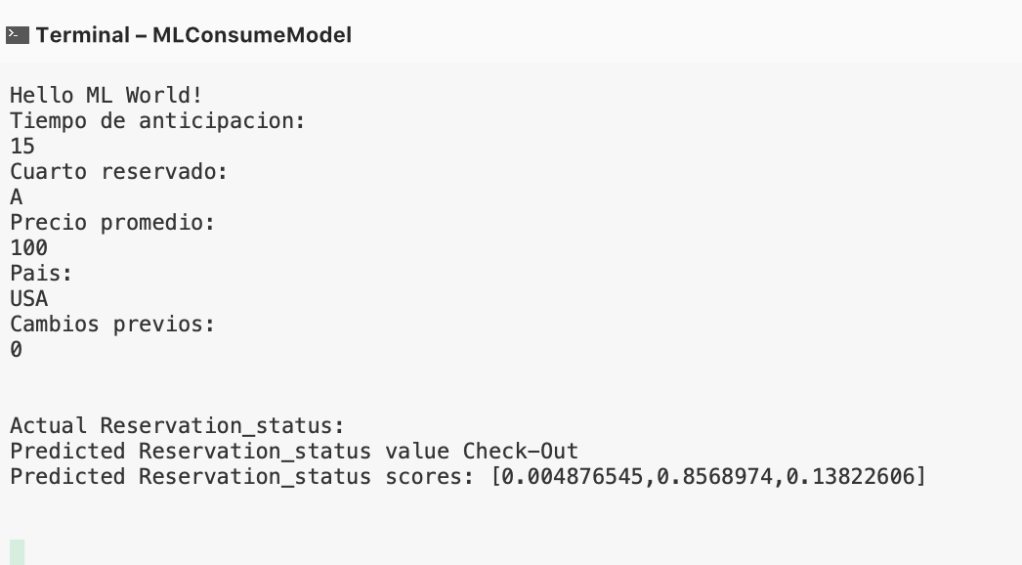
En este caso simulamos la entrada de solo cinco variables de todo el dataset, realizamos la predicción y además vemos la métrica de cada categoría.
El código fuente del proyecto se puede descargar de este repositorio en GitHub
