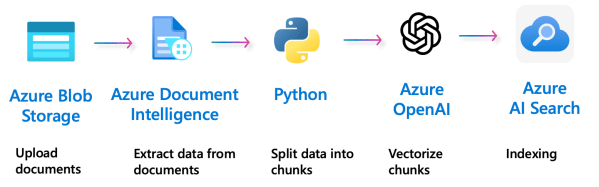
Azure AI Search es un servicio de búsqueda de información que utiliza IA para mejorar la relevancia y precisión de los resultados. Azure AI Search permite indexar información utilizando vectores, lo que significa que puede buscar no solo por palabras clave, sino también por conceptos y relaciones entre términos. Esto es especialmente útil para aplicaciones de Retrival-Augmented Generation (RAG).
Azure AI Search: Cómo optimizar la búsqueda para tus aplicaciones RAG